All You Need to Know About UUIDs

Have you ever been curious about what UUIDs can really do? 😯 Maybe you've seen them around before, like when you're trying to keep track of information in a database, but have you ever stopped to think about their full potential?
This article is here to help you understand the nitty-gritty details of UUIDs.
KEY ASPECTS
UUID is an acronym for Universally Unique IDentifier. It is also known as GUID.
UUIDs are a fast and secure way to identify any type of information. Essentially, they serve as an ideal primary key for your databases.
They are unique; the risk of generating the same ID is close to zero.
They are always made up of 128 bit
The generation process is very fast and safe
There are five versions of UUIDs defined by RFC4122, each suited for different purposes. However, most likely, you will only need to use version 4.
FORMAT
To make it user-friendly, UUIDs are consistently displayed as a sequence of hex numbers with a fixed length. The numbers are categorized into five groups and are united by a hyphen.
970ea114-fa06–472f-acca-df384a39bf7e
Going deeper, the parts are named as follows:
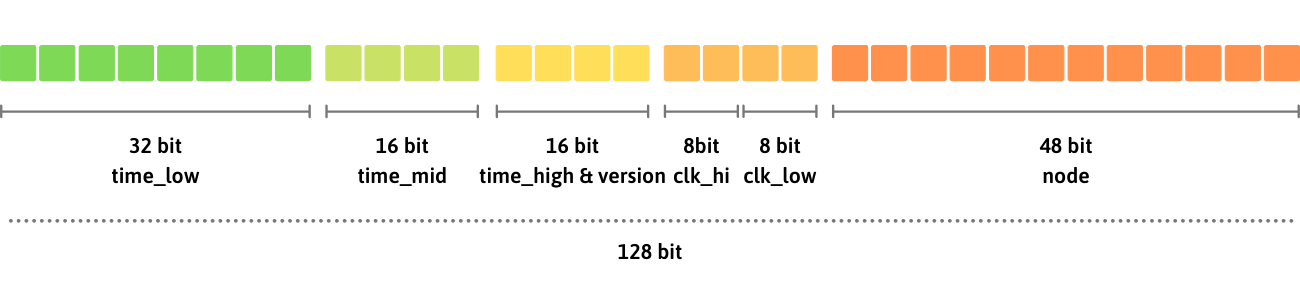
Did you know that UUID version can be determined by checking the first character of the third group?
In the example provided, the UUID version is "4".
VERSION 1: TIMESTAMP and MAC ADDRESS
This version is based on a timestamp and the mac address of the network card, by combining these two parameters we obtain UUIDs that are:
unique over time: the same computer cannot regenerate the same UUID twice, nor during the same timestamp nor in the future
unique over space: UUIDs generated by different computers at the same time will always be different (thanks to their Mac address)
Here’s their composition:
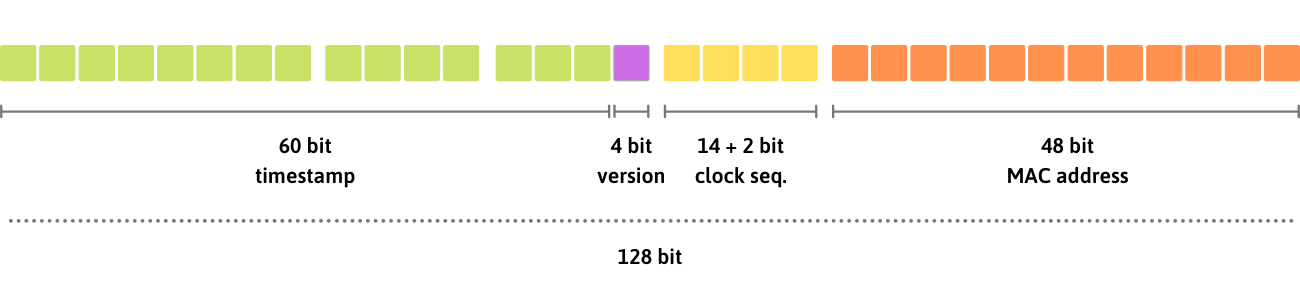
the
timestampis a 60 bit number obtained from the current UTC timestamp, using a resolution of up to 100 microsecondsclock sequenceis a 14 bit unsigned integer used to disambiguate when many UUIDs are made before the timestamp changesMAC address of the primary network card identifier. This value can be faked if a network card is not available.
VERSION 4: RANDOM MADNESS
This is easy: every byte of the UUID is randomic.
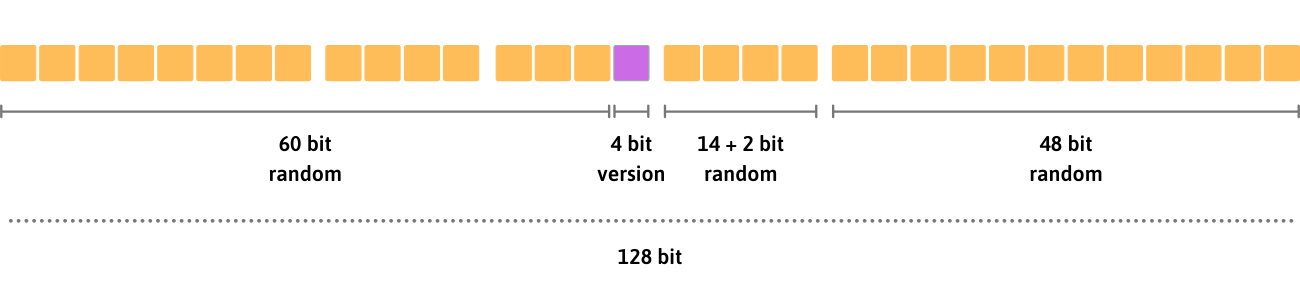
Use this as a general purpose uuid, it will work in almost every scenario.
By involving random operations, generating lots of uuid v4 can be quite slow, consider other versions if you need to generate lots of ids at the same time.
VERSION 5: NAME and NAMESPACE
This version involves two inputs called name and namespace:
nameis any sequence of bytes, such as a stringthe
namespacemust be a valid UUID
UUID v5 is obtained from the sha1 hash of the namespace concatenated with the name, thus leading to a UUID that is predictable:
the same name and namespace will always produce the same UUID
the same name on different namespaces will produce different UUIDs
different names on the same namespace will produce different UUIDs
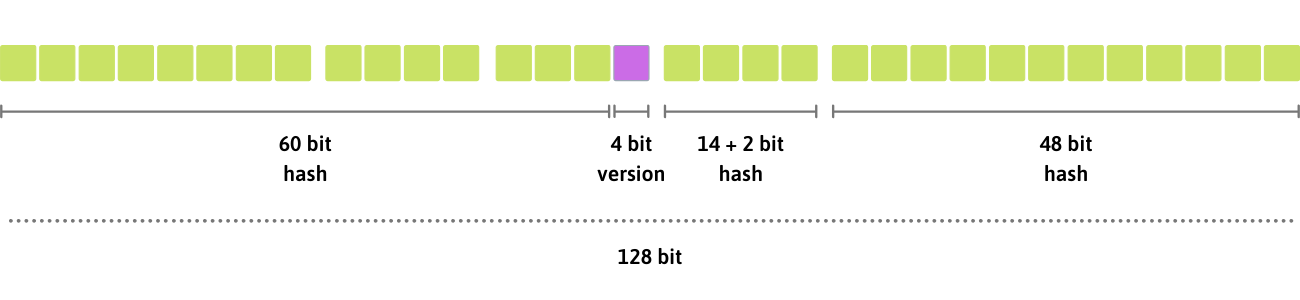
A possible use scenario for this kind of uuid is the storage of encoded passwords in a database or to verify the integrity of a string.
What about version 2 and 3?
version 2 also called “DCE security” is a variant of version 1 that introduces a “local domain” value and a shorter timestamp (only 28 bits).
This version is barely documented and most libraries do not implement it at all, just forget about itversion 3 works just like version 5 but uses md5 instead of sha1, for this reason, it is considered less safe and its usage is discouraged.
